🔐 High Availability & Failover Strategy
This section outlines how Speech Coach is built with reliability and resilience in mind — and what's planned for future improvements.
🧱 What Does HA Mean Here?
To me, an HA-ready version of Speech Coach starts with:
- At least two machines per role (API, DB, worker)
- Redis clustering (2–3 nodes)
- PostgreSQL HA using Patroni + etcd
- MinIO + S3 replication for voice backups
- HAProxy for routing across FastAPI nodes and DB leader
I plan to run load tests to find real bottlenecks before scaling blindly.
💥 What Failure Scenarios Worry Me?
The most critical points are:
- PostgreSQL – user data
- MinIO – audio files (non-recoverable if lost)
These would be my top priorities for redundancy and backups.
🔄 Planned Failover Strategy
If OpenAI API becomes a bottleneck or goes down, I plan to add fallback providers (e.g., Claude, Gemini, local models). That would ensure:
- Lower risk of downtime
- Graceful degradation
📊 Monitoring and SLA Readiness
If I had to hit 99.9% SLA, I'd start with:
- Full monitoring stack (Grafana + Prometheus + Loki)
- Alerting that "shocks" the devs every time something breaks 🫨
- Health checks, auto-restart, and eventually Kubernetes
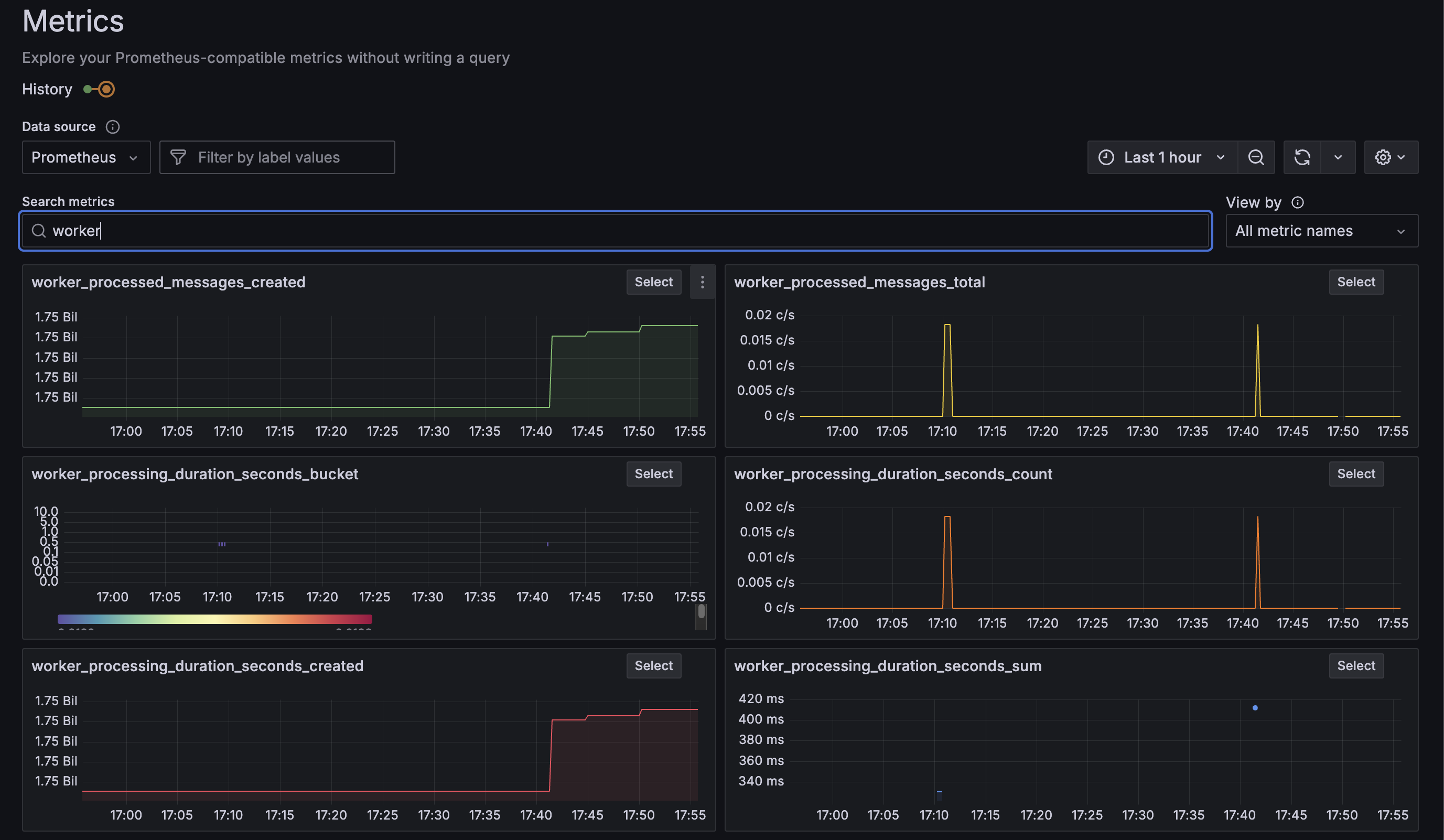 Real-time system metrics and performance monitoring
Real-time system metrics and performance monitoring
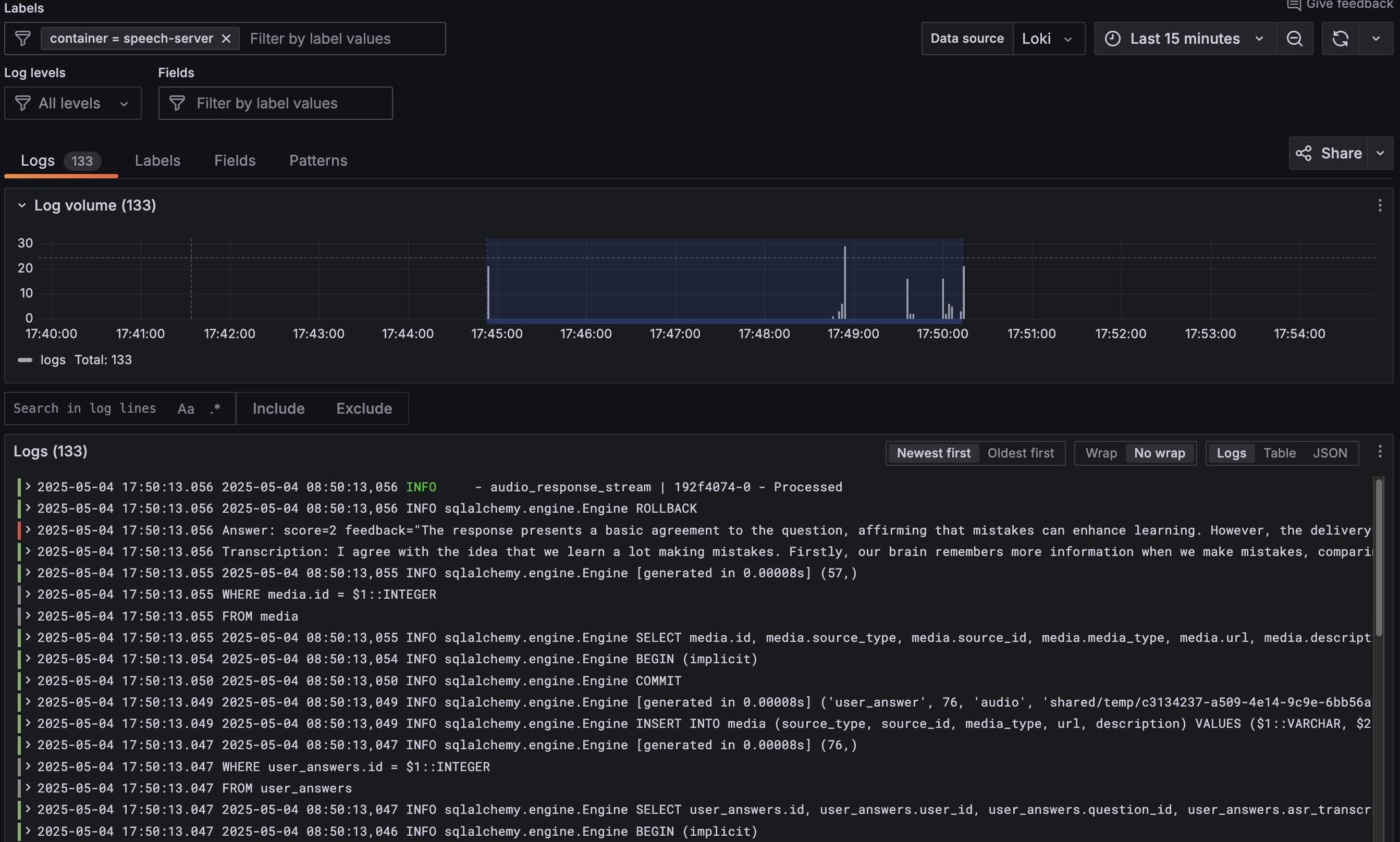 Detailed application logs with error tracking and debugging information
Detailed application logs with error tracking and debugging information
🌍 Cloud Zones?
Currently running on a single VPS — but the architecture is multi-zone ready.